
· 7 min read
Speech to Structure: Strukturált adat kinyerése beszédből
Hogyan alakítható át egy hangfelvétel strukturált, gépileg feldolgozható JSON formátumba AWS-en – Amazon Transcribe, Amazon Bedrock és Step Functions segítségével?
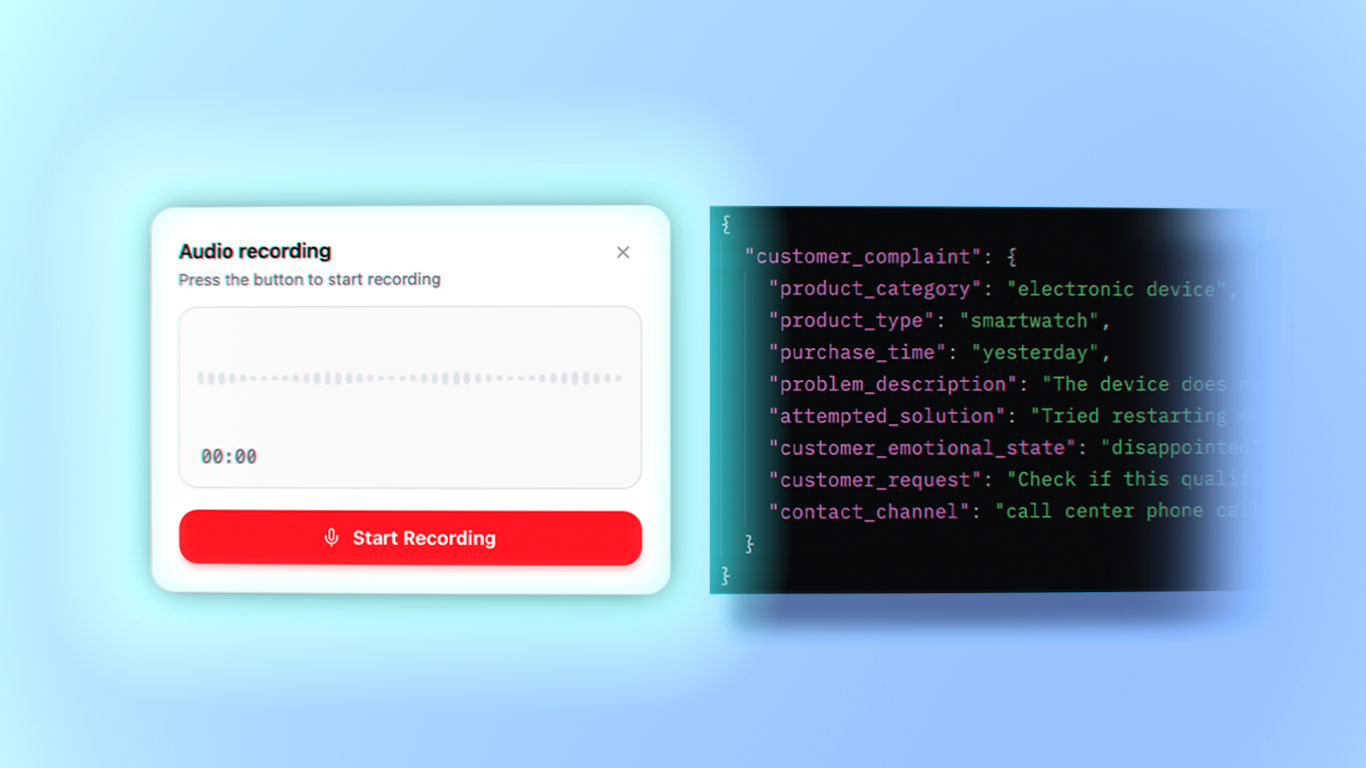
Bevezető
Egy túlterhelt call center környezetben a beérkező ügyfélhívások és üzenetek mennyisége gyakran meghaladja a rendelkezésre álló munkaerő feldolgozási kapacitását. Az ügyfélszolgálati munkatársak idejük jelentős részét azzal töltik, hogy értelmezzék a különböző ügyfelektől érkező, nem strukturált szöveges információkat. Ezek az üzenetek stílusukban, részletességükben és minőségükben is jelentősen eltérhetnek egymástól, ami megnehezíti a gyors és hatékony feldolgozást. Ennek következtében a problémák azonosítása, a releváns információk kinyerése és a megfelelő válasz vagy intézkedés meghatározása gyakran időigényes folyamattá válik. Például:
„Jó napot, tegnap vettem egy új okosórát, de már az első töltés után sem kapcsol be, hiába próbálom újraindítani. Szeretném tudni, hogy ez garanciális hibának számít-e, mert elég csalódott vagyok, hogy egy teljesen új eszköz már az első napon nem működik.”
Probléma és megoldás
A nem strukturált szöveges adatok feldolgozása jelentős erőforrást igényel, mivel az információk kinyeréséhez a teljes szöveg tartalmát és kontextusát értelmezni kell. Az ügyfelek által küldött üzenetek gyakran eltérő részletességgel és megfogalmazásban érkeznek, ezért a releváns adatok azonosítása nehezen automatizálható folyamat.
Ezzel szemben, ha a szabadszavas szöveget strukturált formába tudjuk átalakítani – például kulcs–érték párokból álló dokumentummá, mint egy JSON vagy YAML –, az információk később már könnyen feldolgozhatók programozott módon is. A strukturált adatok lehetővé teszik az automatizált keresést, szűrést és elemzést, például konkrét problématípusok, termékek vagy ügyfelek alapján, ami jelentősen felgyorsítja az ügyfélszolgálati folyamatokat és javítja a hatékonyságot.
{
"customer_complaint": {
"product_category": "elektronikai eszköz",
"product_type": "okosóra",
"purchase_time": "tegnap",
"problem_description": "Az eszköz az első töltés után nem kapcsol be.",
"attempted_solution": "Újraindítás többszöri próbálkozással",
"customer_emotional_state": "csalódott",
"customer_request": "Garanciális hiba ellenőrzése és megoldás",
"contact_channel": "call center telefonhívás"
}
}Előnyök
Az ügyfélszolgálati munkatárs pár másodpercen belül egy strukturál összefoglalót lát a hívást követően, amit később az archívumból is előhívhat.
Az adatbázisból könnyen készíthetünk analízist a beérkező panaszokból vagy kérdésekből.
A strukturált formátumból könnyen kereshetünk és szűrhetünk.
Könnyen integrálhatjuk CRM rendszerekkel vagy ticketing rendszerrel. Használhatjuk logikai elágazásokkal, ha például felveszünk egy problem_type kulcsot device_not_turning_on értékkel, azt közvetlenül továbbthatjuk a garanciális ügyintézéshez.
Megvalósítás
Az általunk megvalósított megoldás egy egyszerű, mégis jól skálázható feldolgozási pipeline-ra épül AWS-en.
A folyamat a frontend felületen indul, ahol a rögzített ügyfélhívás hangfájlját feltöltjük egy Amazon S3 bucketbe, az /inputs prefix alá. Ezt az útvonalat egy EventBridge szabály figyeli, amely az s3:ObjectCreated esemény hatására automatikusan elindít egy AWS Step Functions State Machine-t.
A State Machine két Lambda függvényt futtat egymás után. Az első Lambda az Amazon Transcribe szolgáltatást hívja meg, amely a feltöltött hanganyagból szöveges leiratot készít. A második Lambda ezt a leiratot egy előre definiált strukturális sémával együtt elküldi az Amazon Bedrock felé, amely feldolgozza a szöveget és előállítja a kívánt strukturált kimenetet.
A feldolgozás eredményét végül visszaírjuk ugyanabba az S3 bucketbe, a /summaries prefix alá, ahonnan a frontend vagy más rendszerek már könnyen elérhetik és feldolgozhatják.
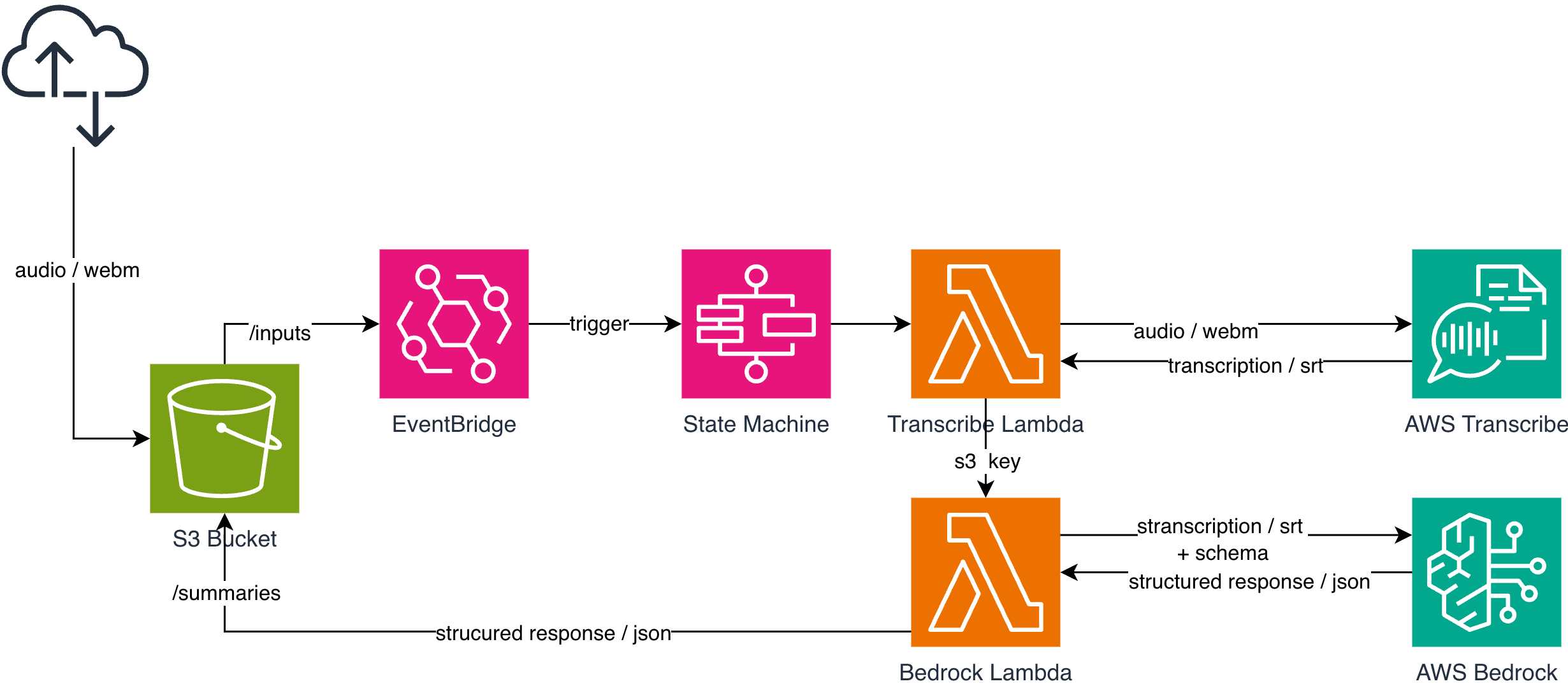
Hogyan működik?
Ebben a példában a frontend alkalmazás egy hangfájlt tölt fel az S3 bucket /inputs útvonala alá. A hangfelvétel származhat közvetlenül a böngészőből rögzített ügyfélhívásból, de ugyanilyen módon feltölthető egy korábban rögzített hanganyag is. A pipeline szempontjából a forrás nem számít: amint a fájl bekerül az /inputs prefix alá, a rendszer automatikusan elindítja a feldolgozási folyamatot.
A feltöltött hangfájl az S3 bucket /inputs útvonalára kerül. Ezt az útvonalat egy EventBridge szabály figyeli, amely az új objektum létrejöttét észlelve automatikusan elindítja a feldolgozási workflow-t.
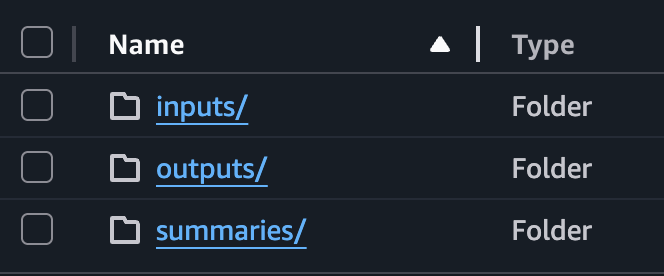
A bucketen belüli különböző prefixek a feldolgozási folyamat egyes fázisait reprezentálják, így jól elkülöníthető, hogy az adott fájl éppen a pipeline melyik lépésében tart. Az S3 útvonalai tehát a következőképpen tükrözik a feldolgozás állapotát:
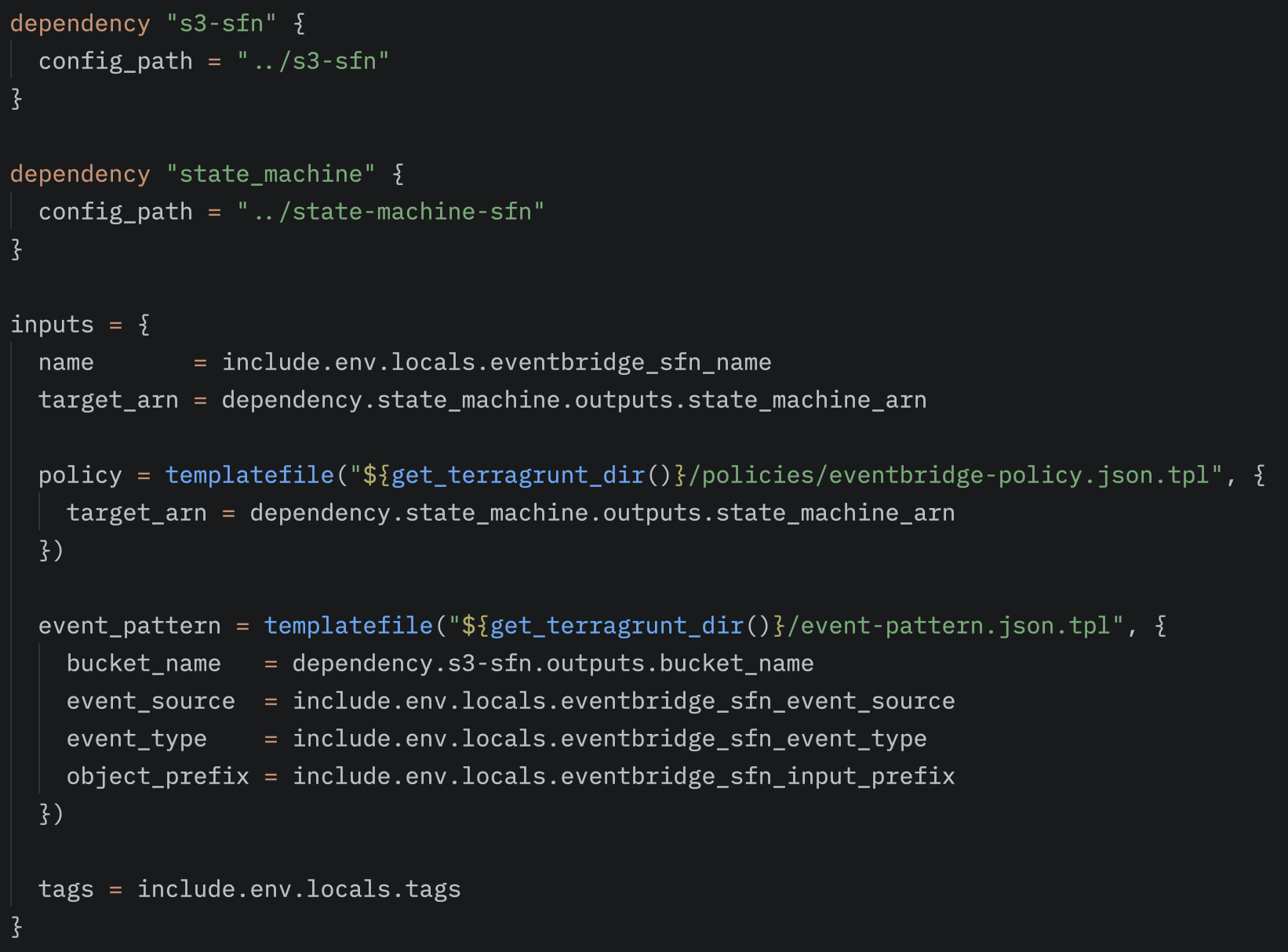
Az EventBridge szabály úgy van beállítva, hogy egy konkrét forrásra figyeljen – a mi esetünkben ez az aws.s3. A szabály az Object Created típusú eseményeket figyeli, és csak azokat a fájlokat indítja el a workflow-ban, amelyek a megadott bucket-ben, az /inputs prefix alatt kerülnek létrehozásra.
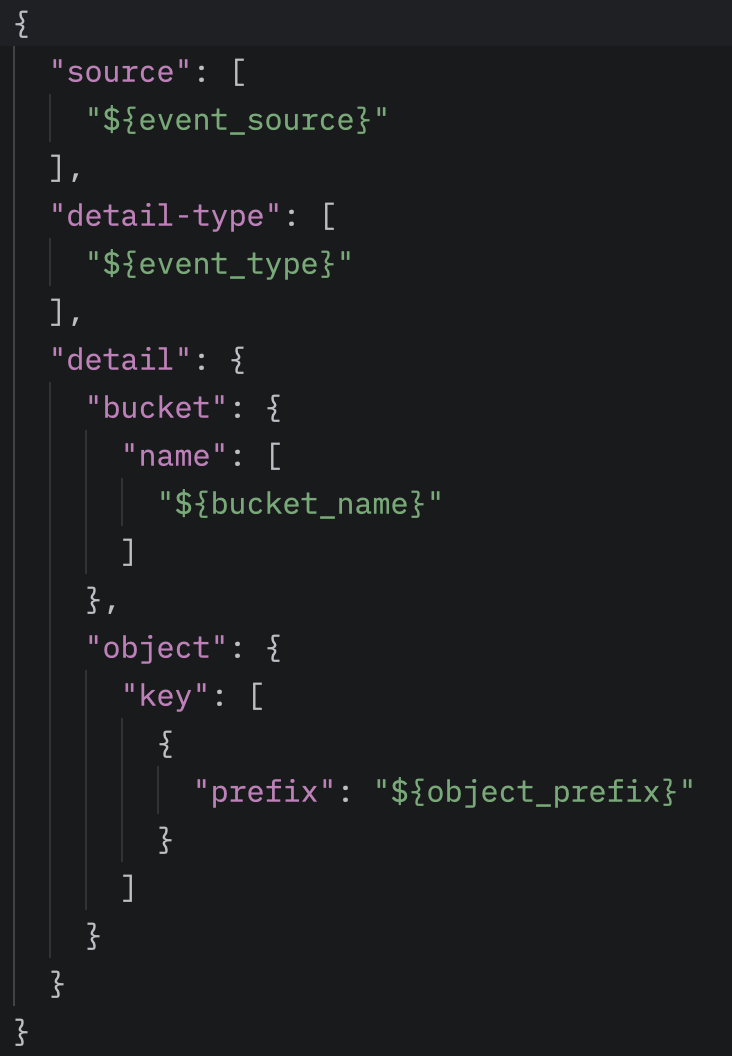
Ahhoz, hogy az EventBridge szabály teljes legyen, meg kell adnunk a célt is, amely a szabály által észlelt eseményekre reagál. A mi esetünkben ez a cél az AWS Step Functions State Machine, amely a feldolgozási pipeline-t indítja el. A szabályhoz az adott State Machine ARN-jét kell hozzárendelni, így minden új objektum az /inputs útvonalon automatikusan elindítja a workflow-t.
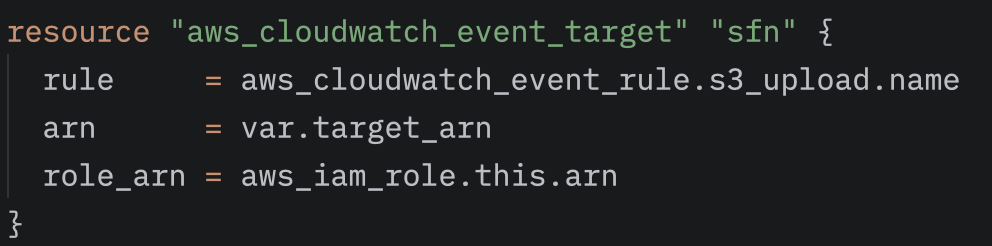
Amint az EventBridge szabály elindítja a State Machine-t, a workflow futtatni kezdi a két Lambda függvényt. Az első Lambda, a Transcribe-Lambda, a hangfájlból készít leiratot amit a /outputs útvonalra tölt fel, és ezt a states.result.Payload mezőn keresztül adja át a második Lambda-nak, a Bedrock-Lambda-nak. (A Payload tartalmazza a leirat S3-beli útvonalát, amely alapján a Bedrock-Lambda hozzáfér a szöveghez, és el tudja végezni a további feldolgozást) Végül a /summaries útvonalon megjelenik a strutkurált összefoglaló.
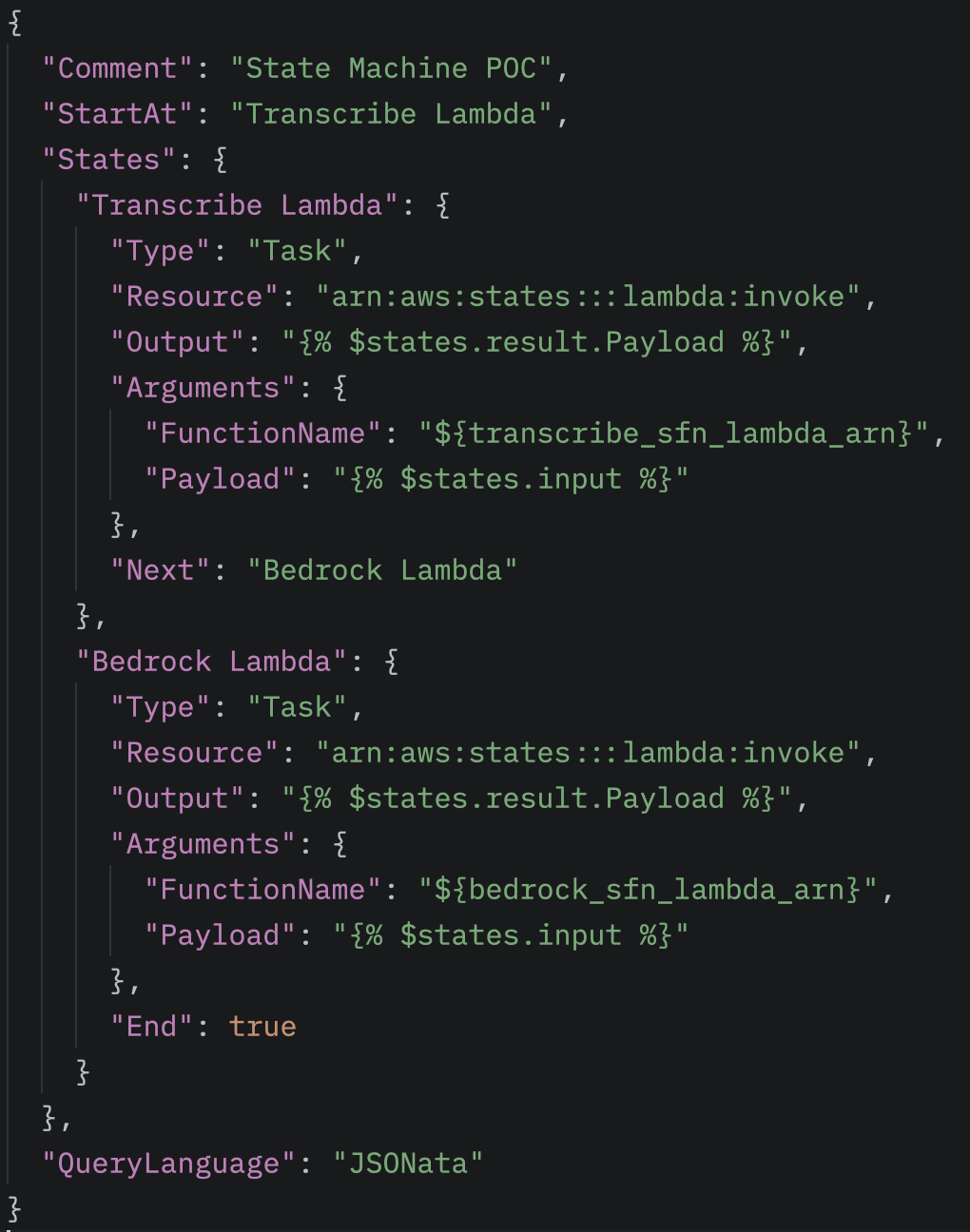
A Transcribe és Bedrock kezelése
A Transcribe egy globális alkalmazás az AWS-en ami azt jelenti, hogy nem tudunk belőle példányt létrehozni a saját fiókunkban, csak az Amazon által üzemeltetett rendszert tudjuk elérni. A szolgáltatás képes automatikus nyelvfelismerésre és több formátumban is vissza tudja adni a leiratot. A JSON formátum az alapértelmezett, amiben a rendszer pontozza az magabiztosságát szavanként, így például pontosságra is tudunk szűrni vele. Ha erre nincs szükségünk beállíthatunk SRT-t is ahogy azt mi is tettük.
Az S3 eventből ki tudjuk olvasni hogy hol találjuk a feltöltött hangfájlt. Ezt az útvonalat fogjuk boto3 segítségével a Transcribe-ba küldeni. Itt paraméterben adhatjuk meg hogy az output hová kerüljön.
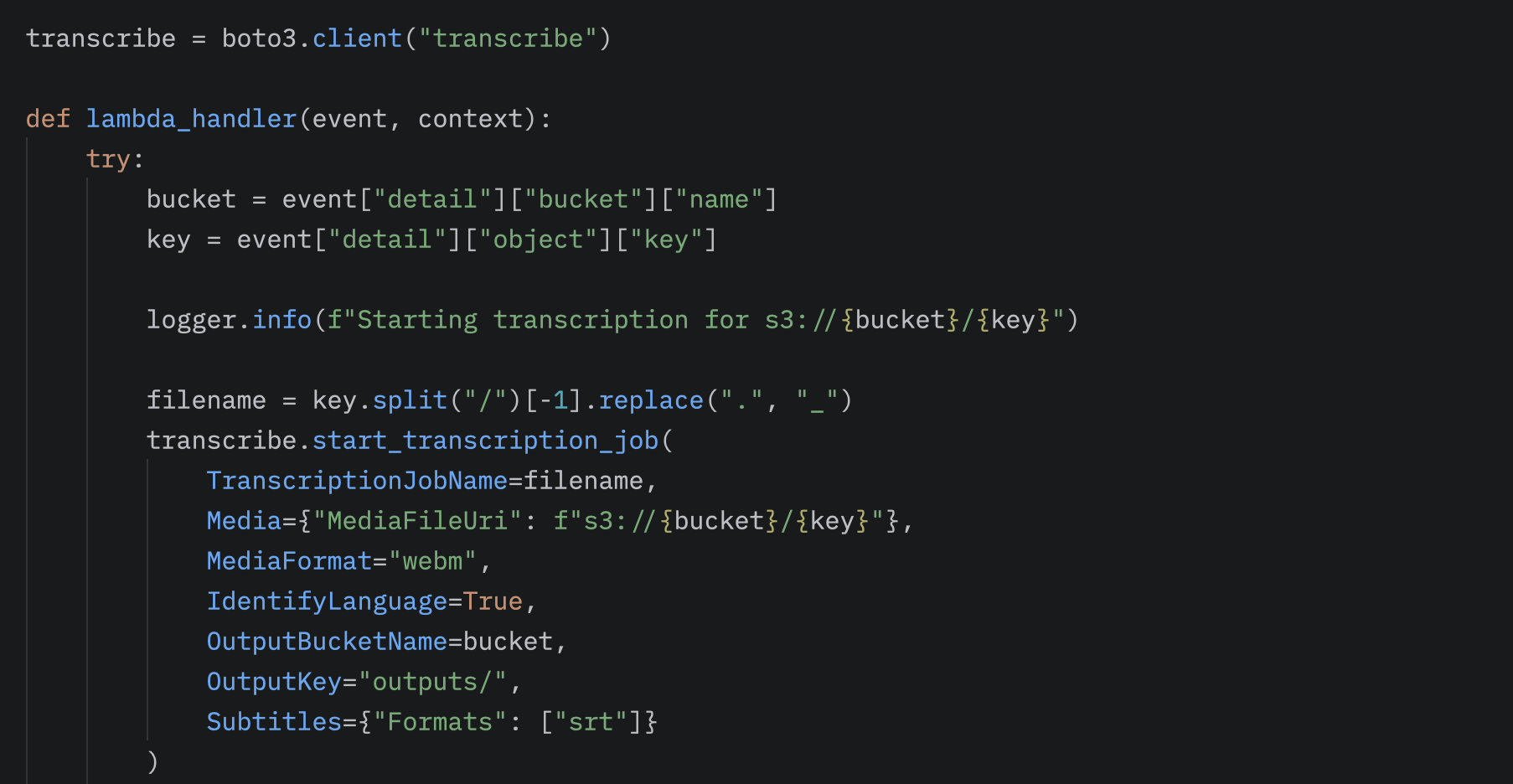
Miután a Transcribe befejezte a leirat elkészítését, a workflow következő lépése a Bedrock-Lambda indítása. Ebben a Lambda-ban szintén a boto3 könyvtár segítségével férünk hozzá az S3-ban tárolt leirathoz, és kommunikálunk az Amazon Bedrock szolgáltatással.
A Bedrock, a Transcribe-hoz hasonlóan, globális és számos kész AI modellhez biztosít hozzáférést, mint a Claude, OpenAI vagy Amazon Nova.
Az első lépés a feldolgozásban a strukturált séma megfogalmazása, amely leírja, hogy milyen formátumban szeretnénk visszakapni a feldolgozott adatot. Ez lehetővé teszi, hogy a Bedrock által generált választ már programozottan, kulcs–érték párok formájában kezeljük, így könnyen integrálható a további automatizált folyamatokba.
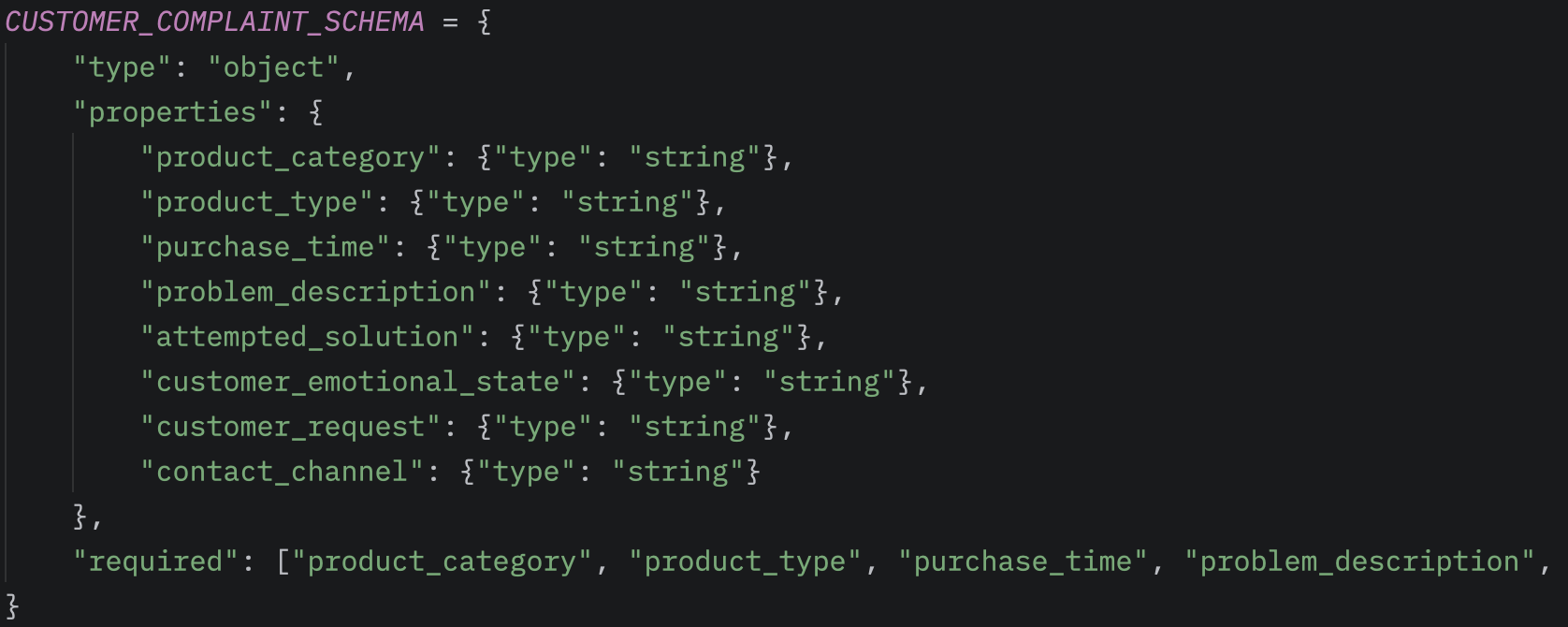
A Bedrock-Lambda feldolgozásában a boto3 bedrock.invoke_model metódusát használjuk a modell meghívására. Itt megadhatjuk a modelId-t, amely kiválasztja, melyik AI modellt szeretnénk használni. Beállíthatjuk a maxTokens értékét a generált válasz hosszának korlátozására és opcionálisan megadhatunk tool-t vagy más speciális beállítást a feldolgozáshoz. Az elvárt strukturált formátumot inputként átadva a modell közvetlenül a fentiekben látott szerkezetben adja vissza a feldolgozott választ.
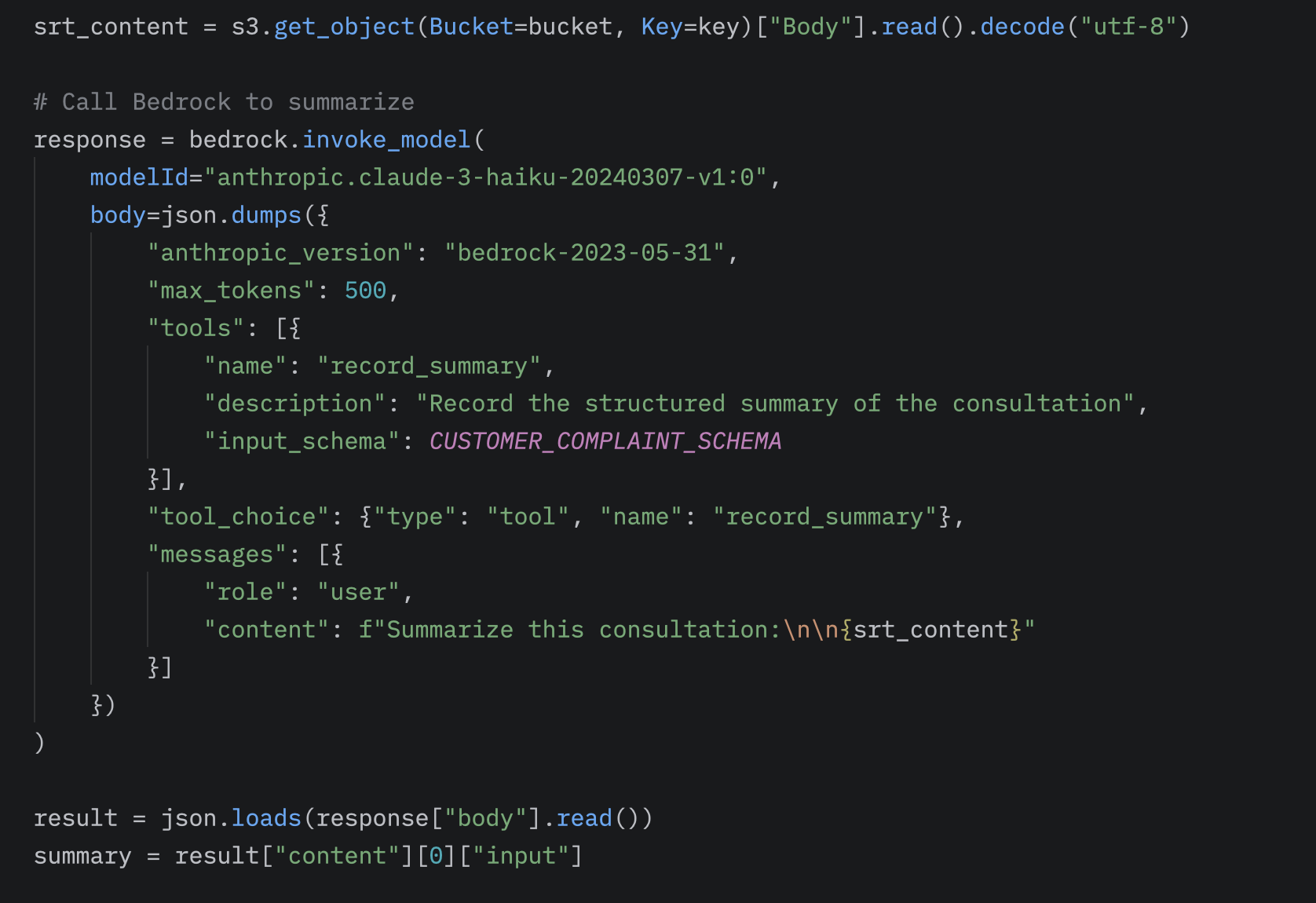
A workflow végeredménye így egy strukturált válasz lesz, amit az S3 /summaries útvonalról további modulokkal feldolgozhatunk vagy visszaadhatunk a kliensnek.
Összegzés
A rendszer be tud fogadni több formátumú hangfelvételt, a frontend felépítésünk miatt mi webm-et használtunk. Ez pillanatok alatt feldolgozásra kerül, ezt a szolgáltatás console oldalán valós időben láthatjuk.
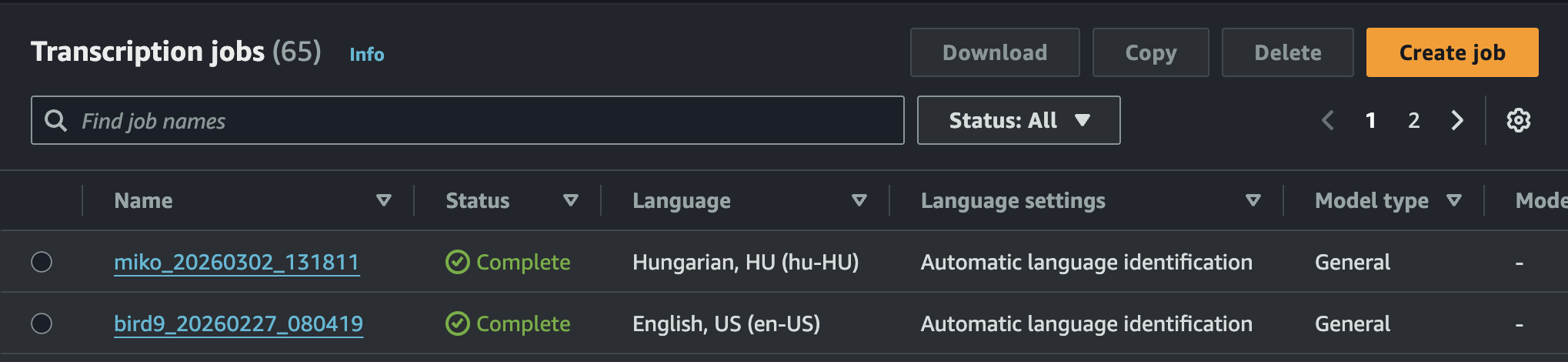
Az összegzést a Bedrock is meglepő gyorsasággal elvégzi és adja vissza a rendszerezett formátumot. Az esetek többségében a hangfájl feltöltése és a végleges válasz visszaadása között körülbelül 15 másodperc telik el, ha a hanganyag hossza 2 perc. Ezt a feldolgozási időt töredékére tudjuk csökkenteni, ha a Transcribe streaming módját használjuk.
A megoldás moduláris jellege miatt könnyen integrálható más rendszerekbe. A folyamat központi eleme az S3 Bucket amiben a részeredményeket külön útvonalakon tároljuk, így abból kikérhetjük az összegzés előtti nyers feliratot vagy a hangfeldolgozást átugorva elindíthatjuk a folyamatot egy szöveges formátummal is, hogy a végén megkapjuk a strukturált összegzést. Az AWS-en kívülről például HTTP protokollal meg tudjuk hívni a szolgáltatást, ami azt jelenti, hogy tetszőleges frontend alkalmazásból mindössze egy REST API végpont meghívásával integrálható a megoldás, platformtól és technológiától függetlenül.
Felhasznált források
- AWS Transcribe: What is Amazon Transcribe? - Amazon Transcribe
- AWS Bedrock: Overview - Amazon Bedrock
- AWS Bedrock Structured output: Get validated JSON results from models - Amazon Bedrock
- AWS State Machines: Learn about state machines in Step Functions - AWS Step Functions
- AWS Lambda: What is AWS Lambda? - AWS Lambda
Kérdésed van? Írj nekünk, és mi segítünk megtalálni a számodra optimális megoldásokat.